
Introduction
De nombreux responsables métiers ou techniques refusent, pour des raisons de sécurité légitimes, de publier leurs données sur une IA, même en environnement contrôlé. Cependant, il est possible de concilier exposition partielle et contrôlée des données HFSQL avec les impératifs de sécurité, conformité RGPD et anonymisation.
Dans le prolongement du PoC « Exposer une base HFSQL à l’IA via MCP », cet article détaille une approche sécuritaire basée sur :
- La pseudonymisation à la volée des identifiants,
- L’exploitation des propriétés RGPD des rubriques HFSQL,
- L’anonymisation des champs mémos
- Une architecture sécurisée via Traefik et clé API.
Cette méthode permet à des systèmes intelligents (LLM, agents, assistants IA) d’interagir avec les données sans jamais accéder directement aux informations sensibles ou identifiantes.
I. Contexte et enjeux métier
1. Définir les risques
Exposer directement des données sensibles (notamment des identifiants ou des données personnelles) via MCP peut entraîner des violations de la vie privée, faciliter des attaques d’ingénierie inversée, ou permettre une exploitation non autorisée.
2. Objectifs techniques
- Masquer les IDs (clé primaire ou autres identifiants sur des données personnelles) à la volée.
- Garantir que seules les rubriques marquées RGPD sont protégées.
- Surveiller et consigner l’usage des données (traçabilité, audit).
II. Architecture technique sécurisée proposée
A. HFSQL : gestion RGPD au niveau des rubriques
PC Soft introduit depuis la version 23 U2 la propriété RGPD dans l’analyse, permettant d’indiquer si une rubrique contient des données personnelles (PCSoft, 2025)
Dans l’éditeur d’analyses, on coche l’option RGPD lors de la description de la rubrique, et même d’effectuer un brouillage partiel de ces données (testeur@testeur.com => texxxx@xxxxxx.com). Cela permet ensuite :
- De filtrer ou de signaler les accès via l’audit RGPD du projet
- De générer un registre des traitements et un dossier imprimable
B. Anonymisation de certaines rubriques à la volée
Certaines rubriques de type Mémo ou Texte libre (ex. commentaires, instructions internes) peuvent contenir des données personnelles implicites, non marquées explicitement comme RGPD dans l’analyse : noms, numéros de téléphone, adresses email, etc. Ce type de contenu est difficile à anticiper mais représente un risque majeur en cas d’exposition à une IA.
1. Limites de la déclaration statique
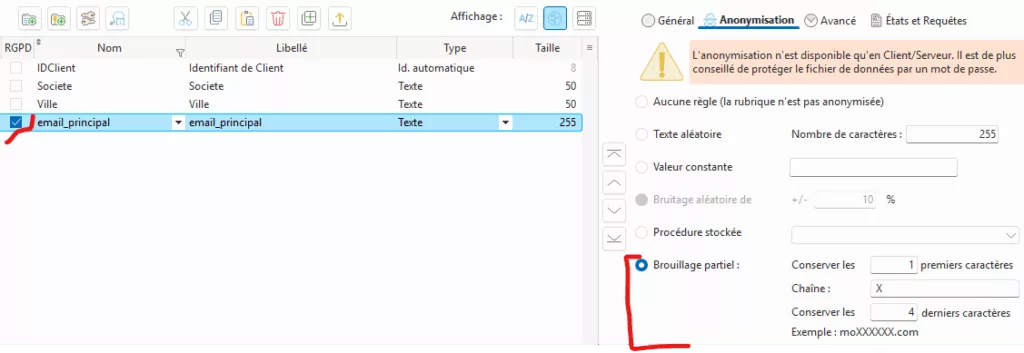
HFSQL permet de marquer une rubrique comme RGPD et d’y associer une règle d’anonymisation (ex. brouillage partiel ou remplacement constant), comme illustré ci-dessous :
Cela est efficace pour des données bien structurées (email, téléphone), mais insuffisant pour du texte libre, où des informations sensibles peuvent apparaître de manière non anticipée.
2. Anonymisation dynamique avec NER local
Pour répondre à cette limite, on peut intégrer un processus d’anonymisation dynamique à la volée, basé sur des modèles de reconnaissance d’entités nommées (NER) exécutés en local, sans appel à une API externe.
Outils recommandés
Ces modèles détectent automatiquement les entités suivantes : PERSON, EMAIL, PHONE, ORG, LOC, etc.
- spaCy : rapide, léger, facile à intégrer dans un microservice Python local (pour rappel, Windev peut exécuter du code Python … ).
- Transformers Hugging Face : plus précis, avec modèles français adaptés (ex.
camembert-base-ner).
Avantages sécurité et performance
- 100 % local : aucun transfert vers un service tiers, données sensibles maîtrisées.
- Rapide et scalable : inférence légère, traitement compatible avec des dizaines de requêtes par seconde.
- Adapté au français : grâce aux modèles francophones pré-entraînés.
- Personnalisable : possibilité d’ajouter des règles métiers (masquer les références client internes, les adresses IP, etc.).
C. Transformation des IDs à la volée (pseudonymisation)
Plutôt que d’exposer directement l’ID interne, on génère un ID externe pseudonymisé :
- Approche : depuis le serveur MCP (développé en WLangage), chaque requête sur un enregistrement transforme l’ID réel en un token anonyme (par exemple en un uuid), que l’IA utilise.
- Implémentation : à la sérialisation des données, les ID sont transformés en uuid.
- Conséquences : l’IA manipule uniquement ces IDs pseudonymes. Pour un usage en lecture seule, on peut rejeter toute tentative de reverse engineering. Pour la réconciliation (ex. suite à une action), le serveur MCP traduit à nouveau l’ID externe en ID interne.
D. Renforcement de la sécurité HFSQL
- Créer un utilisateur pour la base de données exposée à l’IA et lui donner le strict minimum des droits nécessaires à l’utilisation par le MCP.
- Sécurité renforcée : cocher l’option renforce la sécurité des fichiers HFSQL en cryptant la clé via dérivation du mot de passe, empêchant tout traitement automatique sans ce mot de passe, et recommandé pour les données RGPD
- Alertes intrusion : à partir de la version 2025, HFSQL détecte et notifie les tentatives d’accès anormales ou malformées. Pour une sécurité renforcée, il est conseillé de limiter l’accès réseau au serveur HFSQL via le firewall (par IP autorisées uniquement)
E. Exposition sécurisée via Traefik
Dans cette architecture, le serveur MCP est exécuté en natif, et exposé via un reverse proxy Traefik. MCP ne gérant pas les mécanismes complexes d’authentification (redirections, sessions), l’objectif est de garantir une sécurité simple, efficace et compatible avec des appels machine-to-machine.
Objectifs de sécurité :
- Chiffrer les échanges via HTTPS (TLS).
- Restreindre l’accès aux requêtes authentifiées via API key / Secret ID.
- Centraliser la gestion des règles d’accès dans Traefik (middleware).
III. Exemple concret (extraits de configuration & scripts)
A. HFSQL – Définition RGPD et anonymisation
Dans l’analyse HFSQL, chaque rubrique contenant des données personnelles peut être marquée comme RGPD via une simple case à cocher. Cela permet d’intégrer automatiquement cette rubrique aux traitements réglementaires (export, suppression, journal RGPD…).
Pour renforcer la protection, HFSQL propose un système d’anonymisation automatique, disponible uniquement en mode Client/Serveur (PCSoft, 2025).
Exemple : pour un champ email_principal, on peut activer un brouillage partiel en conservant les 1ers et derniers caractères, et en masquant le reste avec une chaîne (ex. moXXXXXX.com). Cette configuration évite l’exposition directe de données sensibles tout en conservant un format lisible.
B. Anonymisation de certaines rubriques à la volée
Ce traitement peut être réalisé à la volée dans un micro service local conteneurisé et intercalé entre le serveur MCP et l’IA ou même intégré au code Windev. Ce service anonymise dynamiquement toutes les rubriques texte désignées dans une whitelist, avant que le contenu ne soit exposé ou transmis
import spacy
from spacy.language import Language
nlp = spacy.load("fr_core_news_md")
texte_origine = "Contacter Mme Durand au 01 01 01 01 01, adresse : 12 rue des Lilas, Lyon."
doc = nlp(texte_origine)
anonyme = texte_origine
for ent in doc.ents:
if ent.label_ in ("PER", "LOC", "ORG", "MISC"):
anonyme = anonyme.replace(ent.text, "[ANONYMISÉ]")
print(anonyme)
# => "Contacter [ANONYMISÉ] au 01 01 01 01 01, adresse : [ANONYMISÉ], [ANONYMISÉ]."Cette anonymisation peut être complétée par l’utilisation d’expressions régulières afin de traiter les numéros de téléphone, …
C. Transformation d’un ID en pseudonymisation
Les fonctions WINDEV HListeFichier, HListeRubrique et HListeLiaison vous permettent de les ID ainsi que les clés associées dans d’autres tables.
Vous avez ainsi la possibilité, lors de la sérialisation des enregistrements envoyés à l’IA, de convertir en ID en un uuid (par exemple) et d’en conserver la trace pour assurer la liaison entre les tables.
D. la sécurité HFSQL
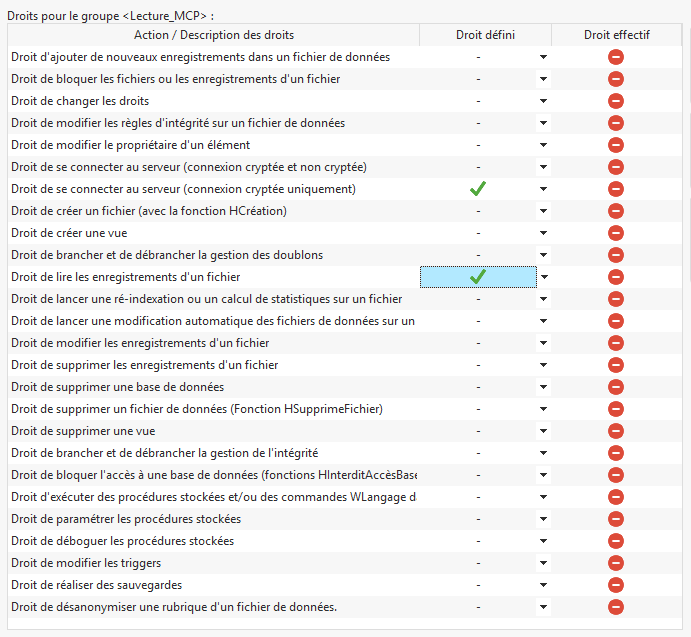
Si le but recherché est de faire analyser des données via une IA, il n’est pas nécessaire d’avoir les droits d’écriture sur la base HFSQL. Un utilisateur avec uniquement les droits de lecture conviendra. Le petit plus, coté sécurité : utilisation d’une connexion cryptée.
E. Exposition sécurisée via Traefik
1. Chiffrement HTTPS avec Traefik
Traefik est configuré pour terminer TLS, c’est-à-dire recevoir les connexions HTTPS, gérer les certificats, et rediriger le trafic sécurisé vers le serveur MCP en local.
2. Authentification par clé API
On définit un middleware de vérification d’un en-tête HTTP personnalisé, par exemple
X-SECRET-ID: secret partagé (peut être hashé côté serveur MCP pour vérification).X-API-KEY: identifiant public
3. Avantages de cette approche
| Élément | Rôle | Avantage |
|---|---|---|
| Traefik | Proxy TLS + filtrage | Chiffrement + filtrage centralisé |
| Clé API | Authentification simple | Compatible MCP, pas de session |
| Header HTTP | Transport du secret | Machine-to-machine, sans interaction UI |
| HTTPS | Sécurisation réseau | Données encryptées sur tout le trajet |
- Aucun accès direct au port du serveur MCP.
- Toute requête passe obligatoirement par Traefik + authentification.
- Les certificats TLS sont gérés de manière centralisée.
- Les journaux d’accès peuvent être consolidés via Traefik (middleware + audit).
IV. Bilan et bénéfices
| Aspect | Bénéfice |
|---|---|
| RGPD par conception | Les rubriques sensibles sont identifiées dès l’analyse (GDPR by Design) |
| Pseudonymisation des IDs | L’IA ne manipule que des tokens anonymes, réduisant le risque d’identification |
| Chiffrement HFSQL | Sécurité renforcée, inviolabilité des données même si fichiers compromis |
| Sécurisation réseau | HTTPS, authentification, et isolation via Traefik |
| Surveillance active | Détection d’intrusion sur HFSQL + audit RGPD alimenté par les logs MCP |
Conclusions
Exposer des données HFSQL à une intelligence artificielle via un serveur MCP n’est pas sans risque — mais ce n’est pas non plus une opération insurmontable. En combinant des mécanismes de pseudonymisation à la volée, une gestion fine des rubriques RGPD, et une architecture d’exposition sécurisée avec Traefik, il devient possible de construire un pont entre la donnée métier et les systèmes d’IA, sans compromettre la sécurité ni la conformité.
L’approche proposée repose sur des techniques simples mais efficaces :
- Les identifiants internes sont systématiquement remplacés par des UUID ou tokens anonymes.
- Les champs textes sont filtrés dynamiquement via des modèles NER locaux (spaCy, Hugging Face), garantissant qu’aucune donnée personnelle implicite ne passe à travers les mailles du filet.
- L’accès à l’API MCP est sécurisé par HTTPS et une authentification par clé API / secret partagé, évitant toute interaction complexe non supportée nativement.
Cette stratégie permet à une entreprise comme IsiNeva de tirer parti de l’IA pour enrichir ses processus (analyse, synthèse, automatisation), tout en conservant le contrôle total sur ses données sensibles.